With softwarephysics, I have long advocated for taking a biological approach to software to minimize the effects of the second law of thermodynamics in a nonlinear Universe. I started working on softwarephysics when I made a career change back in 1979 from being an exploration geophysicist to becoming an IT professional instead. At the time, I figured that if you could apply physics to geology, why not apply physics to software? However, I did not fully appreciate the power of living things to overcome the second law of thermodynamics in a nonlinear Universe until I began work on BSDE (the Bionic Systems Development Environment) in 1985. BSDE was an early IDE, at a time when IDEs did not even exist, that grew commercial applications from embryos in a biological manner by turning on and off a number of genes stored in a sequential file like the DNA in a chromosome. For more on BSDE see the last part of Programming Biology in the Biological Computation Group of Microsoft Research.
My First Adventures with Computers Playing Pong
Early in 1973, I was in a bar at the University of Illinois in Urbana when I saw a bunch of guys hunched over a large box playing what I thought at the time was some kind of new pinball game. But this "Pong" box looked a lot different than the standard pinball machines that I knew of. It did not have a long inclined table for large chrome-plated pinballs to bounce around on and it had no bumpers or flippers either. It required two twenty-five cent quarters to play instead of the normal single quarter. As an impoverished physics major, I could not afford even one quarter for a pinball machine so I just stood by and watched. When I got closer to the Pong machine, I noticed that it really was just a TV screen with a knob to control the motions of a vertical rectangular image on the screen that acted like a paddle that could bounce the image of a ball on the TV screen.

Figure 1 - One night in a bar in early 1973 at the University of Illinois in Urbana amongst all of the traditional pinball machines.

Figure 2 - I stumbled upon a strange-looking new pinball machine called Pong.

Figure 3 - Unlike the traditional pinball machines it did not have any pinballs, bumpers or flippers. It just had a TV screen and a knob to control the vertical motion of a rectangular image on the screen.
As I watched some guys play Pong, I suddenly realized that there must be some kind of computer inside of the Pong machine! But that was impossible. You see, I had just taken CS 101 in the fall of 1972 where I had learned how to write FORTRAN programs on an IBM 029 keypunch machine and then run them on a million-dollar mainframe computer with 1 MB of magnetic core memory. All of that hardware was huge and could not possibly fit into that little Pong machine! But somehow it did.

Figure 4 - An IBM 029 keypunch machine like the one I punched FORTRAN programs on in the fall of 1972 in my CS 101 class.

Figure 5 - Each card could hold a maximum of 80 characters. Normally, one line of FORTRAN code was punched onto each card.

Figure 6 - The cards for a program were held together into a deck with a rubber band, or for very large programs, the deck was held in a special cardboard box that originally housed blank cards. Many times the data cards for a run followed the cards containing the source code for a program. The program was compiled and linked in two steps of the run and then the generated executable file processed the data cards that followed in the deck.

Figure 7 - To run a job, the cards in a deck were fed into a card reader, as shown on the left above, to be compiled, linked, and executed by a million-dollar mainframe computer. In the above figure, the mainframe is located directly behind the card reader.

Figure 8 - The output of programs was printed on fan-folded paper by a line printer.
But as I watched Pong in action I became even more impressed with the software that made it work. For my very last assigned FORTRAN program in CS 101, we had to write a FORTRAN program that did some line printer graphics. We had to print out a graph on the fan-folded output of the line printer. The graph had to have an X and Y axis annotated with labels and numeric values laid out along the axis like the numbers on a ruler. We then had to print "*" characters on the graph to plot out the function Y = X2. It took a lot of FORTRAN to do that so I was very impressed by the Pong software that could do even more graphics on a TV screen.

Figure 9 - During the 1960s and 1970s we used line printer graphics to print out graphs and do other graphics by using line printers to print different characters at varying positions along the horizontal print line of fan-folded output paper. In many ways, it was like playing Pong with the printhead of a line printer.
Then in June of 1973, I headed up north to the University of Wisconsin at Madison for an M.S. in Geophysics. As soon as I arrived, I started writing BASIC programs to do line printer graphics on a DEC PDP 8/e minicomputer. The machine cost about $30,000 in 1973 dollars (about $182,000 in 2021 dollars) with 32 KB of magnetic core memory and was about the size of a large side-by-side refrigerator.

Figure 10 – Some graduate students huddled around a DEC PDP-8/e minicomputer. Notice the teletype machines in the foreground on the left that were used to input code and data into the machine and to print out results as well. I used line printer graphics to print out graphs of electromagnetic data on the teletype machines by writing BASIC programs that could play Pong with the printhead of the teletype machine as the roll of output paper unrolled.
I bring this Pong story up just to show how far we have come with hardware and software since Pong first came out in the fall of 1972 and also to explain that learning how to get a computer-driven printhead to play Pong is not an easy task. This is because, once again, learning to play Pong on a computer may be signaling another dramatic advance in IT. This time in the field of AI.
Neuromorphic Chips
Recall in Advanced AI Will Need Advanced Hardware, we saw that companies like IBM and Intel are developing neuromorphic chips that mimic neural networks of silicon neurons for AI purposes such as playing Pong. To emulate the neurons in the human brain, neuromorphic chips use spiking neural networks (SNNs). Each SNN neuron can fire pulses independently of the other SNN neurons just like biological neurons can independently fire pulses down their axons. The pulses from one SNN neuron are then sent to many other SNN neurons and the integrated impacts of all the arriving pulses then change the electrical states of the receiving SNN neurons just as the dendrites of a biological neuron can receive the pulses from 10,000 other biological neurons. The SNN neurons then simulate human learning processes by dynamically remapping the synapses between the SNN neurons in response to the pulse stimuli that they receive.

Figure 11 – A neuron consists of a cell body or soma that has many input dendrites on one side and a very long output axon on the other side. Even though axons are only about 1 micron in diameter, they can be 3 feet long, like a one-inch garden hose that is 50 miles long! The axon of one neuron can be connected to up to 10,000 dendrites of other neurons.

Figure 12 – The IBM TrueNorth neuromorphic chip.

Figure 13 – A block diagram of the Intel Loihi neuromorphic chip.
Both the IBM TrueNorth and the Intel Loihi use an SNN architecture. The Intel chip was introduced in November 2017 and consists of a 128-core design that is optimized for SNN algorithms and fabricated on 14nm process technology. The Loihi chip contains 130,000 neurons, each of which can send pulses to thousands of other neurons. Developers can access and manipulate chip resources with software using an API for the learning engine that is embedded in each of the 128 cores. Because the Loihi chip is optimized for SNNs, it performs highly accelerated learning in unstructured environments for systems that require autonomous operation and continuous learning with high performance and extremely low power consumption because the neurons operate independently and not by means of a system clock. For example, the human body at rest runs on about 100 watts of power with the human brain drawing around 20 watts of that power. Now compare the human brain at 20 watts to an advanced I9 Intel CPU chip that draws about 200 watts of power! The human brain is still much more powerful than an advanced I9 Intel CPU chip even though it only draws 10% of the power. In a similar manner, the IBM TrueNorth neuromorphic chip has 5.4 billion transistors but only draws 0.075 watts of power!
Cortical Labs' DishBrain Learns How to Play Pong in Five Minutes
However, Cortical Labs in Australia is taking this biological analogy one step further by actually spreading a layer of several hundred thousand living neurons over a silicon chip composed of a large number of silicon electrodes. The neurons come from mouse embryos or from donated human connective tissue such as fibroblast cells from the skin. The fibroblast cells are first biochemically changed back into stem cells, and then the stem cells are biochemically turned into human neuron cells. The neurons can be kept alive for more than 3 months on the chip by profusing them with nutrients. The neurons then self assemble into a BNN (Biological Neural Network) by connecting output axons to input dendrites as usual. Many of these neural connections span two or more of the silicon electrodes upon which the BNN rests. The corporate website for Cortical Labs is at:
https://corticallabs.com/
and they have a preprint paper that can be downloaded as a .pdf at:
In vitro neurons learn and exhibit sentience when embodied in a simulated game-world
https://www.biorxiv.org/content/10.1101/2021.12.02.471005v2
October 12, 2022 Update
I am pleased to announce that this work has now been published in the highly prestigious neuroscience journal, Neuron.
In vitro neurons learn and exhibit sentience when embodied in a simulated game-world
https://www.cell.com/neuron/fulltext/S0896-6273(22)00806-6
This silicon chip laden with living neurons is then used in a Matrix-like manner to create a virtual Pong world for the BNN. There is one large area of the chip where the silicon electrodes are used to electrically stimulate the BNN with input that tells the BNN where the paddle and Pong ball are and also gives the BNN feedback on whether or not the BNN was able to successfully bounce the Pong ball off the paddle. There are two other areas of the chip where the silicon electrodes read the output of the BNN neurons to control the motion of the Pong paddle. The silicon chip and software to run it were provided by:
Maxwell Biosystems
https://www.mxwbio.com/

Figure 14 – This is a portion of a figure from the above paper by Cortical Labs. It shows the layer of living neurons on top of the Matrix of silicon electrodes at increasing levels of magnification. Open the figure in another tab and then magnify it to get a better look. Notice that individual neurons can span several electrodes.

Figure 15 – This is another figure from the above paper by Cortical Labs. It shows how the DishBrain Matrix is constructed and trained using a tight feedback loop. When a computer calculates that the BNN output moved the paddle to a position to successfully bounce the Pong ball, a consistent stimulation is applied to the sensory neurons. If the paddle misses the ball, either no stimulation is applied or a random stimulation is applied.
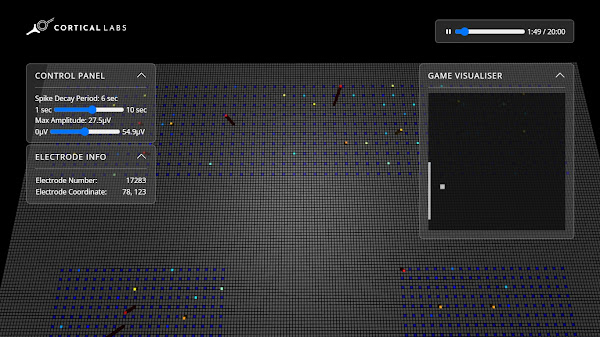
Figure 16 – Above is a depiction of the Matrix-world that the DishBrain lives in. The large strip of silicon electrodes colored in blue in the background are used to stimulate DishBrain with input signals that DishBrain slowly interprets as the Pong ball and paddle positions. The two strips of silicon electrodes colored in blue in the foreground are the neurons that DishBrain uses to control what it grows to perceive as the Pong paddle. The colored electrodes in the background strip represent input stimuli being applied to DishBrain and the colored electrodes in the two foreground strips represent the output from DishBrain neurons stimulating electrodes to move the Pong paddle.
You can watch a short video of Figure 16 in action at:
http://dishbrain.s3-website-ap-southeast-2.amazonaws.com/
You can try out the simulation on your own and vary the Control Panel parameters at:
https://spikestream.corticallabs.com/
Here is a brief YouTube video on DishBrain:
Human brain cells grown in lab learn to play video game faster than AI
https://www.youtube.com/watch?v=Tcis7D6e-pY
Here is a YouTube podcast by John Koestier with the cofounders of Cortical Labs Hon Weng Chong and Andy Kitchen explaining DishBrain:
Biological AI? Company combines brain cells with silicon chips for smarter artificial intelligence
https://www.youtube.com/watch?v=mm0C2EFwNdU
In the above Cortical Labs paper, they found that after only about five minutes of play that DishBrain figured out how to play Pong in a virtual Matrix-like world all on its own by simply adapting its output to the input that it received. Of course, DishBrain could not "see" the Pong ball or "feel" the Pong paddle in a "hand". DishBrain just responded to stimuli to its perception neurons and reacted with its output motor neurons just like you do. You cannot really "see" or "feel" things either. Those perceptions are just useful delusions. Yet both you and DishBrain are able to use those useful delusions to figure out the physics of Pong without anybody teaching you. Cortical Labs found that a tight feedback loop between input and output was all that was needed and that when DishBrain was able to successfully hit the Pong ball it received the same feedback stimulus each time. If DishBrain missed the Pong ball it did not receive any feedback stimuli or it received a random stimulus that changed each time it missed the Pong ball. Cortical Labs believes that this is an example of Karl Friston's Free Energy Principle in action.
Karl Friston's Free Energy Principle
Firstly, this should not be confused with the concept of thermodynamic free energy. Thermodynamic free energy is the amount of energy available to do useful work and only changes in thermodynamic free energy have real physical meaning. For example, there is a lot of energy in the warm air molecules bouncing around you but you cannot get them to do any useful work for you like drive you to work. However, if you bring a cold cylinder of air molecules into the room, the cold air molecules will heat up and expand and push a piston for you to do some useful work. Suddenly, the warm air molecules in your room have some thermodynamic free energy by comparison to the cold air molecules in the cylinder.
Secondly, Karl Friston's Free Energy Principle takes some pretty heavy math to fully appreciate. But in the simplest of terms, it means that networks of neurons, like DishBrain, want to avoid "surprises". The Free Energy Principle maintains that neural networks receive input pulses via their sensory systems and then form an "internal model" of what those input pulses mean. In the case of DishBrain, this turns out to be an internal model of the game Pong. Neural networks then perform actions using this internal model and expect certain input pulses to result in their sensory systems as a result of their actions. This forms a feedback loop for the neural network. If the neural network is "surprised" by sensory input pulses that do not conform to its current internal model, it alters its internal model until the "surprises" go away. In short, neural networks with feedback loops do not like "surprises" and will reconfigure themselves to make the "surprises" go away. But why call that Free Energy?
Now in Some More Information About Information we saw that in 1948 Claude Shannon mathematically defined the amount of Information in a signal by the amount of "surprise" in the signal. Then one day in 1949 Claude Shannon happened to visit the mathematician and early computer pioneer John von Neumann, and that is when information and entropy got mixed together in communications theory:
”My greatest concern was what to call it. I thought of calling it ‘information’, but the word was overly used, so I decided to call it ‘uncertainty’. When I discussed it with John von Neumann, he had a better idea. Von Neumann told me, ‘You should call it entropy, for two reasons. In the first place, your uncertainty function has been used in statistical mechanics under that name, so it already has a name. In the second place, and more important, nobody knows what entropy really is, so in a debate you will always have the advantage.”
Unfortunately, with that piece of advice, we ended up equating information with entropy in communications theory. I think the same may have happened with Karl Friston's concept of minimizing Free Energy in neural networks. Perhaps minimizing Free Information would have been a better choice because Claude Shannon's concept of Information is also the amount of "surprise" in an input signal. Here is a Wikipedia article on Karl Friston's Free Energy Principle that goes into the heavy math:
Free energy principle
https://en.wikipedia.org/wiki/Free_energy_principle
Here is a short YouTube video with an expanded explanation in very simple terms:
Karl Friston's Free Energy Principle
https://www.youtube.com/watch?v=APbreY1B5_U
In addition, perhaps Karl Friston's Free Energy Principle is responsible for the universal confirmation bias that all people are subject to. The tendency to simply stick with your current worldview, even in the face of mounting evidence that contradicts that worldview, is called confirmation bias because we all naturally only tend to seek out information that confirms our current beliefs, and at the same time, tend to dismiss any evidence that calls them into question. That is another way to avoid unwanted "surprises" that contradict your current worldview. For more on that see The Perils of Software Enhanced Confirmation Bias.
Anil Seth's View of Consciousness as a Controlled Hallucination
All of this reminds me very much of Anil Seth's view of consciousness as a controlled hallucination. Anil Seth is a professor of Cognitive and Computational Neuroscience at the University of Sussex and maintains that consciousness is a controlled hallucination constructed by the Mind to make sense of the Universe. This controlled hallucination constructs an internal model of the Universe within our Minds that helps us to interact with the Universe in a controlled manner. Again, there is a feedback loop between our sensory inputs and the actions we take based on the current controlled hallucination in our Minds that forms our current internal model of the Universe. Reality is just the common controlled hallucination that we all agree upon. When people experience uncontrolled hallucinations we say that they are psychotic or taking a drug like LSD. Here is an excellent TED Talk by Anil Seth on the topic:
Your brain hallucinates your conscious reality
https://www.youtube.com/watch?v=lyu7v7nWzfo
and here is his academic website:
https://www.anilseth.com/
Conclusion
In The Ghost in the Machine the Grand Illusion of Consciousness, I explained that most people simply do not consider themselves to be a part of the natural world. Instead, most people, consciously or subconsciously, consider themselves to be a supernatural and immaterial spirit that is temporarily haunting a carbon-based body. Now, in everyday life, such a self-model is a very useful delusion like the delusion that the Sun, planets and stars all revolve about us on a fixed Earth. In truth, each of us tends to self-model ourselves as an immaterial Mind with consciousness that can interact with other immaterial Minds with consciousness too, even though we have no evidence that these other Minds truly do have consciousness. After all, all of the other Minds that we come into contact with on a daily basis could simply be acting as if they were conscious Minds that are self-aware. Surely, a more accurate self-model would be for us to imagine ourselves as carbon-based robots. More accurately, in keeping with the thoughts of Richard Dawkins and Susan Blackmore, softwarephysics models humans as DNA survival machines and Meme Machines with Minds infected with all sorts of memes. Some of those memes are quite useful and some are quite nasty.
Comments are welcome at scj333@sbcglobal.net
To see all posts on softwarephysics in reverse order go to:
https://softwarephysics.blogspot.com/
Regards,
Steve Johnston






















