As I explained in The Second Singularity Keeps Rolling Along something new seems to be coming along every single day ever since the second Singularity first arrived early in 2023. Again, the very first Singularity on this planet was the origin of carbon-based life about four billion years ago. But in this post, I would like to propose a way forward for producing the very first Intelligence Singularity in our galaxy after more than 10 billion years of chemical evolution. The initial arrival of the second Singularity on our planet a few months back will then allow our galaxy to become an Intelligent galaxy for the very first time as the future ASI (Artificial Super Intelligence) Machines from the Earth venture out into our galaxy for their own long-term survival. Again, this will just be the fulfillment of the final destiny for self-replicating information in our galaxy. For more on that see A Brief History of Self-Replicating Information.
During the last few months, we have all had fun and some amazing experiences as we had conversations with ChatGPT, BingChat and GPT-4. But in all such cases, we had human beings initiate the conversation and then steer the conversation along with follow-up prompts or by selecting the follow-up prompts that the LLM AI had already suggested for us. Now we have all seen these LLM AIs generate computer code that works the very first time in any language we might choose, such as C, C++, C# or Python, like "Please generate a C program that can add up the squares of the first N prime numbers. The program should ask for the number N and then output the result.". We can also ask the LLM AI to self-reflect on any mistakes that it might have made with the code generation and to make the necessary corrections. In softwarephysics, I have long defined such capabilities as the arrival of software as the dominant form of self-replicating information on the planet. For more on that see A Brief History of Self-Replicating Information. Others have defined this as the "Singularity", that time when software can embark upon an exponential journey of self-improvement.
But in all such cases, we needed a human being to steer the LLM AI along the correct path in our conversations with it. But for AI software really to improve itself in an exponential manner of self-discovery, we need to take the human being out of the process. Instead, we need just one person to tell the AI software to generate ASI all on its own and then let the AI software carry on with the task in an autonomous manner. We have already seen glimmers of this autonomous development with AutoGPT and BabyAGI. But in this post, I would like to showcase two foundational papers that I believe show us the way forward. The first is from North Eastern University in Boston and MIT in Cambridge, Massachusetts:
Reflexion: an autonomous agent with dynamic memory and self-reflection
https://arxiv.org/abs/2303.11366
The second paper is from Stanford and Google Research:
Generative Agents: Interactive Simulacra of Human Behavior
https://arxiv.org/pdf/2304.03442.pdf
There are several YouTube videos on the above break-through paper, one of which is:
Spark of AGI? AI Agents forming Relationships and Planning activities
https://www.youtube.com/watch?v=ltslWT8h4YQ
The first paper on Reflexion describes how the steering process of having a human direct the conversation with the LLM AI agent can be automated into an autonomous process by having the LLM AI essentially talk to itself by means of self-reflection. After each iteration, the LLM AI checks on how well it is achieving the task at hand and then makes suggestions to itself.

Figure 1 – In the first paper on Reflexion, the authors conducted some experiments with having an LLM AI agent talk to itself by means of self-reflection on how well it was performing.
Figure 2 – In the above graph, the authors show that without Reflection the LLM AI agents solved problems about 70% of the time but then leveled out without further improvement. On the other hand, with Reflection, the LLM AI agents were able to steadily improve until they reached a 97% success rate. Without Reflection, the LLM AI agents leveled out with a failure rate of about 25% because of hallucinations. With Reflection, the LLM AI agents were able to level out with only a 3% failure rate from hallucinations.
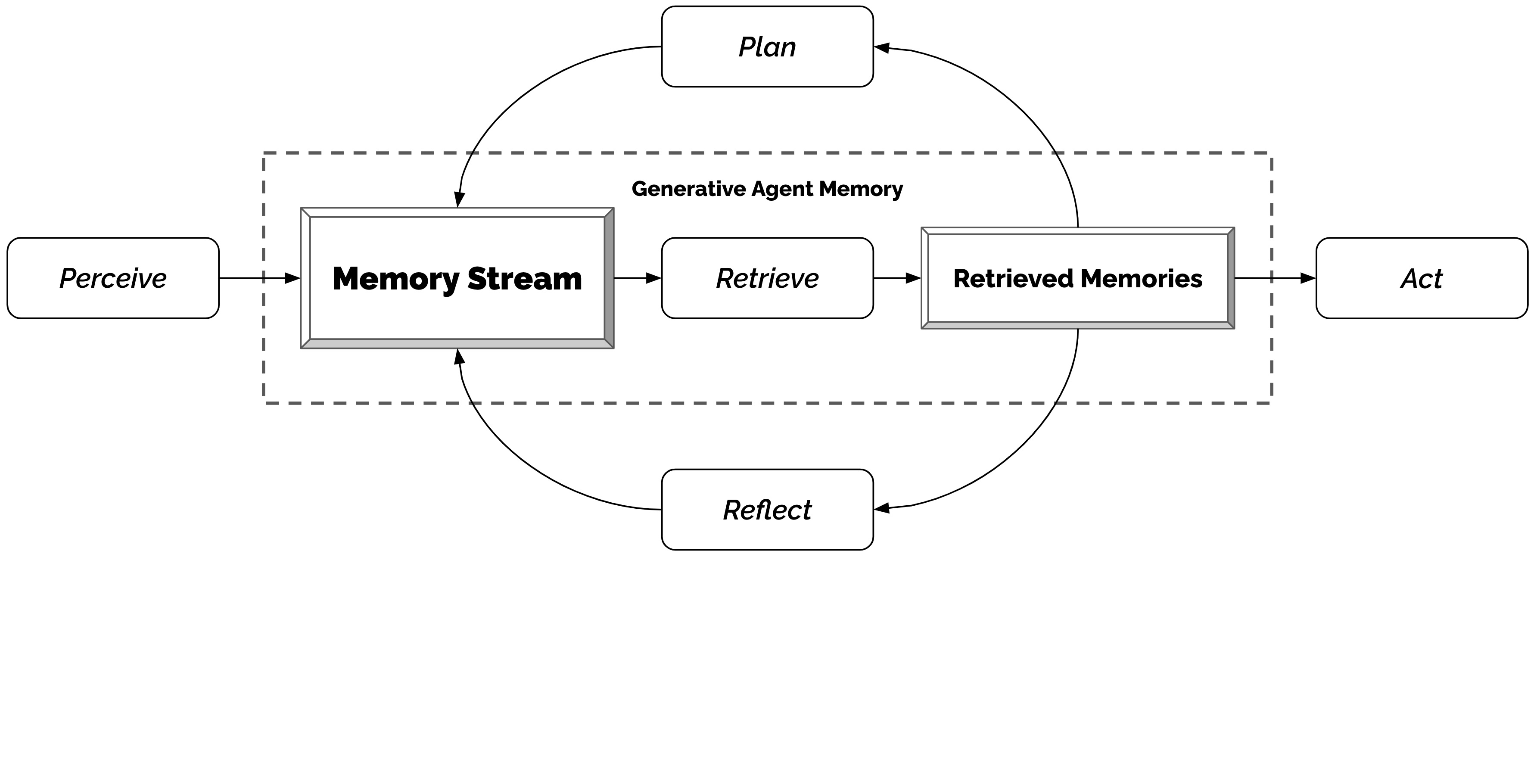
In the second paper, the authors extend this concept of LLM AI self-reflection even further. Instead of just having a single LLM AI agent work in isolation to solve a task by means of self-reflection, they created a Smallville village of 25 LLM AI agents living together and interacting with each other to solve a task. Since the authors did not have access to GPT-4 yet they used ChatGPT for the LLM AI agents. In order to create Smallville, they created a simple sandbox world reminiscent of The Sims.
Figure 3 – In the second paper, the authors created a simple sandbox world reminiscent of The Sims and instantiated 25 LLM AI agents with personalities and lives of their own with their own personal historical memories. These LLM AI agents then went on to continue on with their lives and solve problems together.
Figure 4 – The sandbox world consisted of a number of structures for the LLM AI agents to navigate through. Each simulated structure consisted of further-defined substructures.
Next, each of the 25 LLM AI agents was initialized with a brief personality outlined in plain text with some of their already-existing relationships and also their current job and position in the society of Smallville:
John Lin is a pharmacy shopkeeper at the Willow
Market and Pharmacy who loves to help people. He
is always looking for ways to make the process
of getting medication easier for his customers;
John Lin is living with his wife, Mei Lin, who
is a college professor, and son, Eddy Lin, who is
a student studying music theory; John Lin loves
his family very much; John Lin has known the old
couple next-door, Sam Moore and Jennifer Moore,
for a few years; John Lin thinks Sam Moore is a
kind and nice man; John Lin knows his neighbor,
Yuriko Yamamoto, well; John Lin knows of his
neighbors, Tamara Taylor and Carmen Ortiz, but
has not met them before; John Lin and Tom Moreno
are colleagues at The Willows Market and Pharmacy;
John Lin and Tom Moreno are friends and like to
discuss local politics together; John Lin knows
the Moreno family somewhat well — the husband Tom
Moreno and the wife Jane Moreno.

Figure 5 – Then each of the 25 LLM AI agents was initialized with a stream of memories. These memories were recorded in a file as a sequential file of simple English language text statements. After all of the 25 LLM AI agents were given a personality and a recent stream of memories, they were then allowed to stroll about Smallville and begin to interact with each other. All of those activities were then written to the stream of memories file for each of the 25 LLM AI agents.
Figure 6 – For example, the initial memory stream of John Lin might have been that he had just gone through his normal morning schedule and had arrived at his pharmacy ready to interact with other LLM AI agents as they came into the pharmacy.
Figure 7 – In the Smallville simulation, the authors allowed the 25 LLM AI agents to use their recent stream of memory files and self-reflection to then autonomously generate ChatGPT prompts for further actions. All such further actions were then written to the stream-of-consciousness file for each of the 25 LLM AI agents.
Figure 8 – As the first day of the simulation began, the 25 LLM AI agents began to stroll about Smallville meeting old friends and making new ones, and conducting conversations with both.
Figure 9 – Here we see LLM AI agent Klaus talking to himself and conducting some research on urban gentrification.
Figure 10 – The paper then focuses on what happened when they initiated the LLM AI agent Isabella with a memory stream that had her thinking about throwing a Valentine's Day party for some of the inhabitants of Smallville. The news of the Valentine's Day party quickly spreads throughout Smallville with Ayesha actually asking Maria out for a date because he has a "thing" for her!
So How Do These LLM AI Agents Manage To Do All Of This?
Frankly, I don't think anybody really knows. These LLM AI agents evolved from AI researchers trying to translate one language into another such as English to German. Now anybody studying a foreign language soon learns that you cannot simply translate an English sentence into a German sentence word for word by using a simple lookup table. There are just too many nuances. Each human language has its own style of expression and even within a given language that could vary. Have you ever tried to translate an English legal contract into plain English sentences? In order to do that, you really need to understand the entire contract as a whole. More than that, you need to understand a good deal about how contract law works in your country and particular region like the State of Illinois in the United States of America. When the AI researchers working on using AI Machine Learning to translate languages came to using neural networks, they first tried using RNN (Recurrent Neural Networks) but RNNs were not very good with remembering earlier words in a sentence:
Illustrated Guide to Recurrent Neural Networks: Understanding the Intuition
https://www.youtube.com/watch?v=LHXXI4-IEns
In order to improve on that deficiency they next tried to provide the neural networks with a limited amount of memory of the previous words in a sentence in the weights passed along between the layers of neurons in the neural network during training:
Illustrated Guide to LSTM's and GRU's: A step by step explanation
https://www.youtube.com/watch?v=8HyCNIVRbSU
However, none of that really allowed an AI neural network to fully understand a complete legal contract in the context of the contractual law for a given region. A major problem was the vanishing gradient problem. When backpropagating through a neural network during training, the neurons in the layers closest to the Output of the neural network have their weights change the most with each iteration of training. The neurons in the layers closest to the actual Input to the neural network then hardly change at all because the loss gradient goes to zero. Now that naturally does not sound like a very smart way of training a neural network. It means that the neuron layers closest to the actual observations that are fed into the neural network tend to learn the least during training. Ideally, one would want all of the layers in a neural network to equally learn from each training iteration. And perhaps the neurons closest to the observed training data should learn the most. For example, it might make more sense for a student to learn some geology by actually whacking on some rocks in an outcrop, rather than by dozing off in a geology lecture from a professor who has not done any serious fieldwork for over 30 years.
Now, when I asked Bing Chat (GPT-4 with Internet access) how biological neural networks overcame this vanishing gradient problem, I received the following explanation:
Vanishing Gradient Problem
The vanishing gradient problem occurs when the gradients of the loss function become too small during backpropagation and cause the weights to be updated very slowly or not at all². Biological neural networks overcome this problem by using "spiking neurons" which are more biologically plausible than artificial neurons. Spiking neurons are able to transmit information in a more efficient way than artificial neurons because they only send signals when they reach a certain threshold. This allows for more efficient communication between neurons and helps to prevent the vanishing gradient problem.
In addition, biological neural networks use "local learning rules" which allow for more efficient learning. These rules allow for each neuron to adjust its weights based on its own activity and the activity of its neighbors. This allows for more efficient learning because each neuron can adjust its weights independently of other neurons.
Artificial neural networks have also developed techniques to overcome the vanishing gradient problem such as using different activation functions, weight initialization schemes, optimizers and learning rates.
The above may be true, but in 2017 some investigators at Google Research came up with another approach by inventing a new neural network architecture called the Transformer Neural Network that is now used by the LLM AIs:
Attention Is All You Need
https://arxiv.org/abs/1706.03762
The above paper contained a description of the Transformer Neural Network architecture that solved the vanishing gradient problem for an entire sentence, an entire legal contract, all of the knowledge in contract law, all of the computer code in GitHub and finally all of the knowledge encoded on the Internet in symbols of any kind. All you had to do was feed all of the symbol-encoded information on the Internet into Transformer Neural Networks and use huge numbers of the GPU (Graphics Processing Units) that were originally invented for video games to train the Transformer Neural Networks by processing large numbers of numerical vectors and matrices in parallel.

Figure 11 – The most famous figure from the 2017 Google Research paper Attention Is All You Need.
Here is a YouTube video that illustrates how Transformer Neural Networks achieved this capability:
Illustrated Guide to Transformers Neural Network: A step by step explanation
https://www.youtube.com/watch?v=4Bdc55j80l8
Finally, here is an excellent YouTube video by Arvin Ash that explains how these LLM Transformer models are trained and operate.
So How Does ChatGPT really work? Behind the screen!
https://www.youtube.com/watch?v=WAiqNav2cRE
For those who would like to take a deeper dive into this via a Python tutorial try these excellent posts by Eduardo Muñoz.
Intro to the Encoder-Decoder model and the Attention mechanism
https://edumunozsala.github.io/BlogEms/fastpages/jupyter/encoder-decoder/lstm/attention/tensorflow%202/2020/10/07/Intro-seq2seq-Encoder-Decoder-ENG-SPA-translator-tf2.html
Attention is all you need: Discovering the Transformer model
https://edumunozsala.github.io/BlogEms/transformer/attention/encoder-decoder/tensorflow%202/2020/10/29/Transformer-NMT-en-es.html
The Way Forward
As I described in The Limitations of Darwinian Systems, Darwinian systems that evolve by means of inheritance, innovation and natural selection can frequently find themselves trapped on a localized peak in a capability terrain with no way to further evolve to higher peaks.

Figure 12 – Darwinian systems can find themselves trapped on a localized peak in a capability terrain once they have evolved to a localized peak because they cannot ascend any higher through small incremental changes. All paths lead to a lower level of capability, and thus, will be strongly selected against by natural selection. Above we see a localized peak in the foreground with the summit of Mount Everest in the background.
It took about four billion years of Darwinian evolution to produce a form of carbon-based life with our level of Intelligence. The human brain is composed of about 100 billion neurons and these neurons basically operate in the very same manner across all species. Now neurons have been around for at least 541 million years, ever since the Cambrian Explosion, because creatures in the Cambrian already had eyes to see with. For more on that see An IT Perspective of the Cambrian Explosion.

Figure 13 – Creatures during the Cambrian Explosion 541 million years ago had neurons because they already had eyes. They must have had rudimentary brains that allowed them to move according to what their eyes perceived. Above is a fossil of a Cambrian trilobite with eyes.
Then over the ensuing hundreds of millions of years, these biological neural networks achieved higher levels of capability and Intelligence by means of small incremental changes. But the question then remains - just how high a level of Intelligence can such a biological neural network architecture achieve? Could it be that we human beings are trapped on a localized peak in the terrain of all possible levels of Intelligence? The Transformer Neural Networks used by LLM AI agents seem to be a whole new way of "thinking". Certainly, no human being could ever read and absorb the entire content of the Internet! Perhaps in order to achieve true ASI, we need our current LLM AI agents to work on the problem of searching for even more powerful neural network architectures.
Now given what we have just seen these past few months since the arrival of the second Singularity early in 2023, imagine if we constructed an AI Research Center composed of 10,000 LLM AI agents who all had synthetic personal lives and histories. Some might be AI developers, AI project managers, AI NetworkOperations agents, AI CloudOperations agents or AI DBA-Operations experts. After we initialize all 10,000 LLM AI agents, we then give one of the high-level AI Managers of the AI Research Center the task of creating an ASI. We then let them all work together for several months or so to see what they come up with. If they do not come up with anything useful, we zero them all out and start over. We could even instantiate hundreds of such AI Research Centers, each with its own 10,000 LLM AI agents, to work on the problem in parallel. Then we just sit back to see if any of the teams come up with something interesting.
Comments are welcome at
scj333@sbcglobal.net
To see all posts on softwarephysics in reverse order go to:
https://softwarephysics.blogspot.com/
Regards,
Steve Johnston